
【官方】Google 发布《生成式 AI 搜索优化指南》及相关讨论
这份文档是 Google Search Central 发布的官方指南,发布于 2026 年 5 月 15 日。这是 Google 对于“如何为 Google Search 的生成式 AI 功能优化网站”的官方立场声明,覆盖 AI Overviews 和 AI Mode。
SEO 在 AI 搜索时代还有用吗?
有用,而且是根基。Google 的生成式 AI 功能依赖两个关键技术,二者都基于现有的搜索索引:
- RAG(检索增强生成 / Grounding):AI 不是凭空回答,而是先用 Google 核心搜索系统从索引中检索出相关、及时的网页,再基于这些页面生成回答,并附带可点击的来源链接。
- Query fan-out(查询扇出):模型会自动衍生出一组相关查询并发执行。例如用户问“如何处理满是杂草的草坪”,系统可能同时搜索“最佳除草剂”、“无化学除草方法”、“如何预防杂草”等。
关于 AEO / GEO:Google 明确表态——从它的角度看,这些都只是 SEO 的不同叫法,不需要把它们当成独立学科。
我的看法:跟之前 Google 在 Search Live 上讲的一致——好的 SEO 就是好的 GEO(反过来也是)。
要做的事:把 SEO 基本功用在生成式 AI 搜索上
1. 创造有价值、非通用内容【这是最重要的一条】
- 独特视角:基于亲身经历、第一手评测的内容比“网上信息汇编”更有价值。AI 自己就能拼凑通用内容,它需要的是“网上还没有的东西”。
- 非通用内容:
- 反例(通用内容):《首次购房者的 7 个建议》——人人都能写。
- 正例(非通用内容):《为什么我放弃验房却省了钱:下水道线路实录》——有独家经验。
- 结构清晰:使用段落、小节、标题,方便人类阅读。
- 配高质量图片和视频:AI 回答里也会嵌入相关图片视频,多一个曝光通道。
- 不要为每个查询变体单独建页:试图覆盖所有 fan-out 查询会触发滥用规模化内容政策,且长期无效。
- 用 AI 辅助创作可以,但成品必须符合搜索规范和反垃圾政策。
2. 保持清晰的技术结构
- 页面必须能被索引、能在 Google 搜索中有摘要展示,才有资格进入 AI 功能。
- 遵循爬取最佳实践,大型/高频更新站点要关注抓取预算。
- 语义化 HTML 不需要追求完美,关注人类可读性即可——但对屏幕阅读器和 AI agent 友好。
- 使用 JavaScript 框架要遵循JavaScript SEO 最佳实践。
- 良好的页面体验(速度、移动适配、主体内容清晰)。
- 减少重复内容。
- 用 Search Console 监控问题。
3. 本地商家和电商要做好结构化数据源
- 电商接入 Merchant Center(feeds)。
- 本地商家用 Google Business Profile。
- 可考虑 Business Agent(让用户能在搜索里直接对话品牌)。
我的看法:以上准则对 SEO 和 GEO 都适用。
澄清:你不需要做的事
这一节是这份指南最有信息量的部分,Google 直接点名了一批流行的“AEO/GEO 流行操作”:
| 流行说法 | Google 官方态度 |
|---|---|
| llms.txt 等“AI 专用文件” | 不需要。Google 不会因此特殊对待。 |
| 把内容“切块(chunking)”成小片段方便 AI 理解 | 不需要。Google 能理解一个页面上多主题的细微差异,没有“理想页面长度”。 |
| 为 AI 重写内容、堆长尾关键词 | 不需要。AI 能理解同义词和语义意图。 |
| 到处刷“品牌提及” | 没用。反垃圾系统会过滤这些操作。 |
| 过度堆砌结构化数据 | 不是必需。结构化数据该用还是要用,但不要为 AI 而做。 |
我的看法:我之前也做过相关澄清,但 Google 更权威,也更彻底。
了解 Agentic 体验(前瞻)
AI agent 正在能代替用户执行任务(订座、比价等)。浏览器 Agent 会通过截图、DOM 结构、accessibility tree 来理解你的网站。
如果你有余力,可以:
- 参考打造 Agent 友好的网站。
- 关注新兴协议如 Universal Commerce Protocol (UCP)。
相关讨论
这篇文档发布之后,引起了非常热烈的讨论。首先就是怀疑 Google 说话不可信,Google 已经在用 llms.txt 和 Markdown 文档,比如:
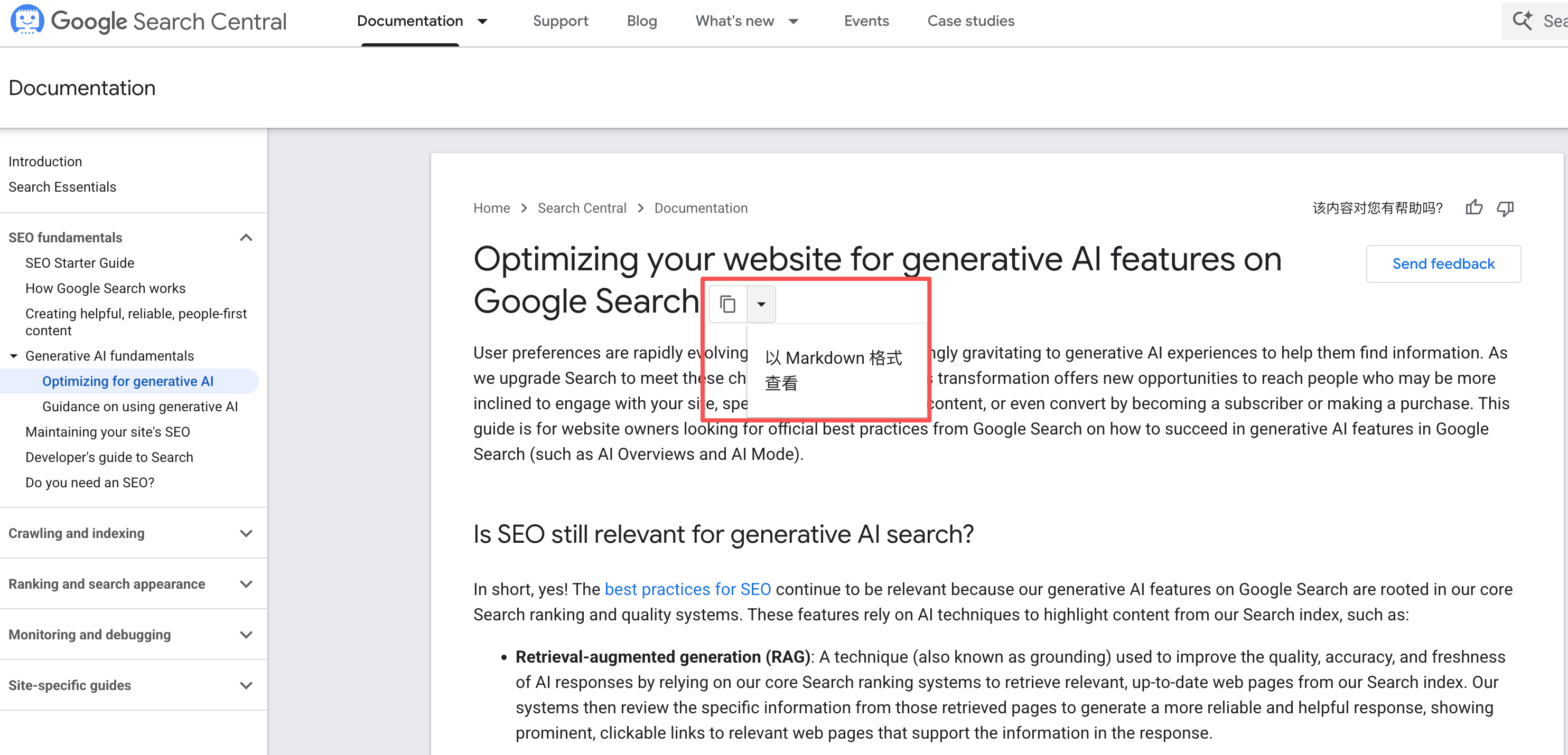
- 原文的这篇文档就提供了查看 Markdown 版本,如上图。
- Chrome 浏览器的文档《Agentic browsing audits》中也专门介绍了 llms.txt。
对于这个问题,Google 搜索关系团队的 John Mueller 也做出了回应:
(官方文档这个功能)是内容管理系统的功能,这并不是为了搜索而做。可能只是一种临时措施,帮助阅读者直接把 Markdown 内容输出给 AI,以节省 Token,长期看来意义并不大。
这里借用一下申永的看法:
由于 AI 的不完美,需要做 llms.txt、Markdown 格式内容,各种内外内容投喂,还要分场景分群体,包装自己的品牌包装自己的产品,真是有点折腾人,很多人为概念,为浪潮买单,效果只有自己知道。是不是随着 AI 的发展,这些都是过程,就像谷歌刚热起来的时候,各种关键词堆砌,各种泛域名解析,各种垃圾外链一样,随着发展还是回归用户,回归用户价值。现在很多公司都不想在 AI 赛道落后,花费大量的钱去做 GEO,服务商帮你一起梳理你公司的定位,你公司的产品,你公司的服务,说是公司资产沉淀,信就去做吧,对也不对,对的是你公司从来没有这样系统的梳理过这些工作,不对的是效果真的那么好吗?这些事情不还是回归到 SEO 的路子,只是一种变种而已,你没觉得传统 SEO 更符合用户更符合实际吗,现在为了 AI 制造出这么多东西出来,后面怎么清洗呢?
我的判断也类似:
llms.txt、内容分块、Markdown 镜像网页,可能都是短期有效的。就像关键词密度和关键词堆砌,在 SEO 早期是有效的一样——搜索引擎依靠关键词密度来判断相关性,所以前期非常有效,也催生了大量关键词堆砌的作弊行为。后期搜索引擎能力提升,逐渐依靠向量算法、自然语言等算法来计算相关性,关键词密度就逐渐失效,甚至成为作弊信号之一。同理,llms.txt、内容分块、Markdown 镜像网页等也是一样:因为 AI 前期能力和策略有限,只能用这些简单的方法,所以会短期有效。但这些策略产生了新的问题,或影响了用户体验,所以长期来看不会被支持,将慢慢消失在历史长河。
原文链接:Optimizing your website for generative AI features on Google Search
【报告】Microsoft Clarity 推出全新 AI 可见度报告
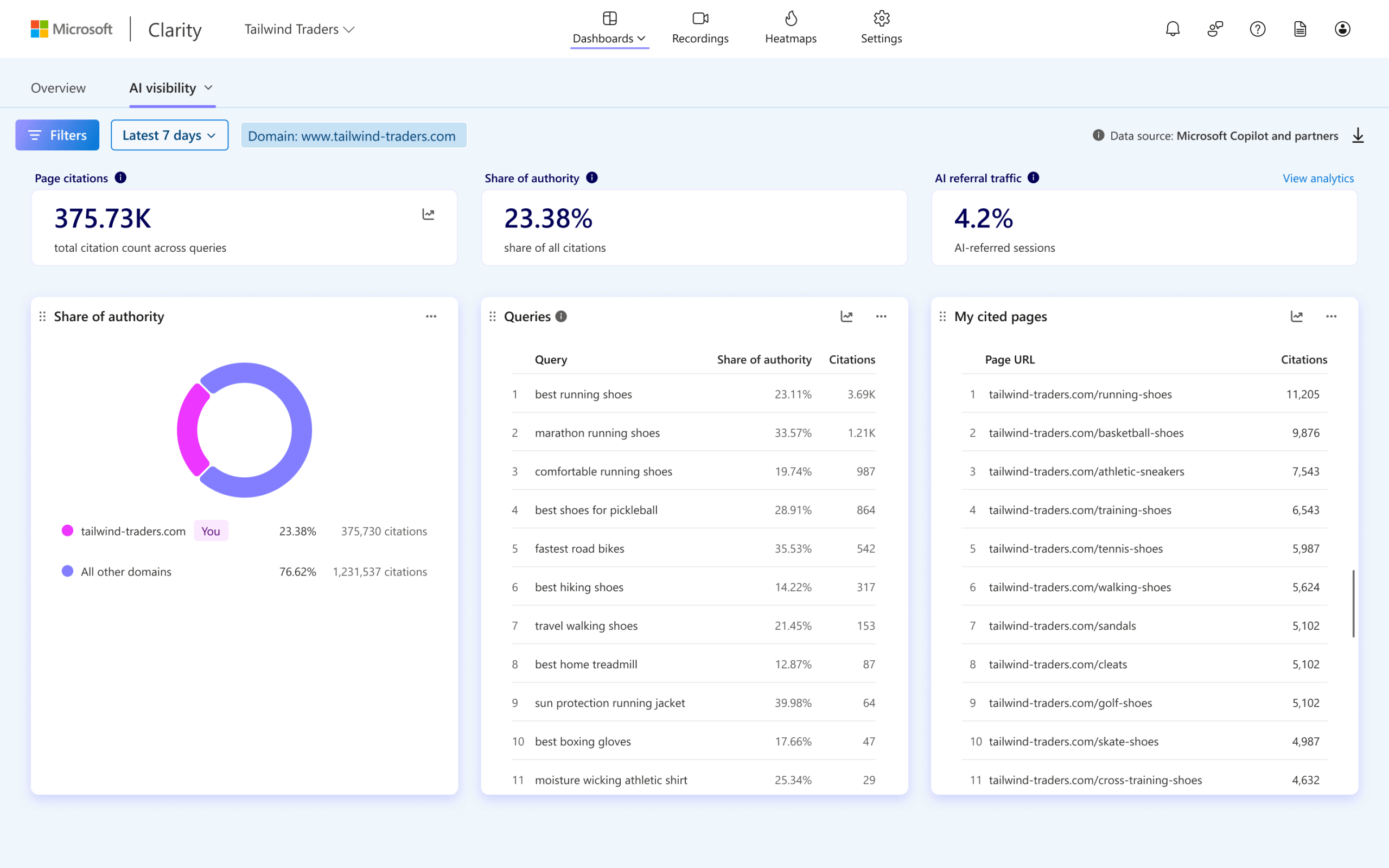
Microsoft Clarity 中新增了 AI 可见度报告,该报告帮助网站主了解自己内容在 AI 答案中的可见性——你的页面何时被发现、被引用、被用作 AI 系统的“引用”(grounding)来源。
核心指标
| 指标 | 说明 |
|---|---|
| 页面引用数 (Page Citations) | 你的域名页面被 AI 回答引用的总次数 |
| 权威份额 (Share of Authority) | 在同一组查询中,你的域名所占引用总量的百分比,可做竞品对比 |
| AI 引荐流量 (AI Referral Traffic) | 来自 AI 助手的会话占网站总会话的百分比 |
| 搜索词 (Queries) | AI 系统用来检索和评估你网站内容的搜索词,帮助理解用户意图 |
| 被引用页面 (My Cited Pages) | 页面级视图,展示哪些 URL 被引用及关联的查询 |
| 趋势线 (Trendlines) | 追踪被引用页面和查询随时间变化的趋势 |
如何使用
- 创建 Clarity 项目并在网站安装 Clarity 追踪代码即可自动开始获取数据。
- 部分情况需通过绑定 Bing Webmaster Tools 或 Google Search Console 完成域名验证。
- 访问路径:Dashboards → AI Visibility → Citations。
未来规划
即将推出的功能包括:
- 主题洞察(Topic Insights):自动将被引用的查询按意图主题分组,帮助理解内容“为什么”被 AI 选中。
- 竞品与归因分析:更丰富的竞争对比和内容贡献度分析。
- 可执行的建议:帮助填补内容空白、在关键话题上建立权威、更频繁地出现在 AI 回答中。
补充一点:强烈推荐安装下 Clarity。不光是新推出的 AI 可见度报告,Clarity 本身就是微软推出的免费工具,能查看网站热力图,也可以免费录制用户的访问会话。
原文链接:Citations now generally available
其他更新
- GA4 新增 “AI Assistant” 默认渠道分组:GA4 终于把 ChatGPT、Gemini、Claude 的流量从 Referral 里单独拎了出来,自动归入新的 “AI Assistant” 渠道,无需自己写正则;不过 Perplexity 和 Microsoft Copilot 暂未在官方名单中。
- Google 澄清:垃圾信息政策也适用于 AI Overviews / AI Mode:Google 在 spam policies 文档的开头加了一句话——操纵 AI 生成回答的技术也算垃圾行为,Google 会采取行动。
【案例】行之有效,直到失灵:那些适得其反的AI内容策略
Lily Ray 跟踪了 220 多个 AI 内容平台的“客户案例”网站,发现超过半数站点出现腰斩级流量下滑。崩盘模式也高度一致:
- 6-12 个月内容爆发。
- 3-6 个月达到流量峰值。
- 之后一年内崩盘到低于基准线。
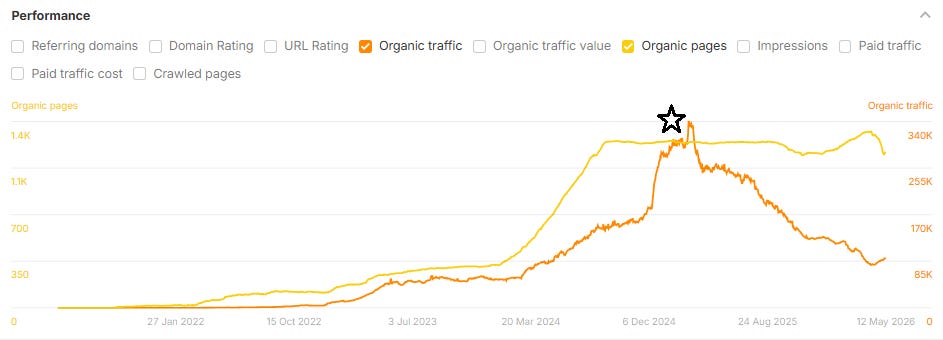
网站流量崩盘的统计数据:
| 跌幅 | 站点占比 |
|---|---|
| ≥30% | 54% |
| ≥50% | 39% |
| ≥75% | 22% |
历史回顾:
- 2023.9 Helpful Content Update:打击“为搜索引擎而非人类写的内容”。
- 2024.3 Core Update + Scaled Content Abuse 政策:Google 自己宣称要把低质量、非原创内容减少 45%,明确瞄准“为操纵排名而批量生产页面,无论作者是人还是 AI”。
Lily 的判断:现在 AI 工具产出的内容,和当年被这两波更新干掉的内容长得几乎一模一样——只是生产成本更低、规模更大。
八种高风险 AI 内容模板(哪种命中越多,跌得越狠)
| # | 模板 | 典型 URL 模式 |
|---|---|---|
| 1 | 规模化产品对比页 | /blog/[产品A]-vs-[产品B] |
| 2 | “什么是 X” 词汇表 | /glossary/[术语] |
| 3 | “最好的 X for Y” 清单 | 经典 affiliate 套路 |
| 4 | 自我推销清单(最危险) | 在“最佳 X”榜单里把自己排第 1,竞品排后面 |
| 5 | 竞品替代品页 | /blog/[竞品]-alternatives |
| 6 | 程序化地域 / 多语种扩展 | 没有真实本地业务却假装覆盖每个城市 |
| 7 | FAQ 农场(每问一页) | /faq/[问题] |
| 8 | 与业务无关的话题(笑话、宝宝名、星座) | 跨主题刷量 |
她特别强调:这些套路真的能短期排上去——所以才有人用——但一旦规模化,对算法来说就是非常显眼的特征。
“2026 年 1 月晚期未确认更新”:Lily 发现至少 40 个站点从 2026-01-20 左右开始下跌 40-95%,主要命中“自我推销清单”模式。这可能只是 Google 打击 GEO 操纵的开端。
如何安全地使用 AI 内容工具
她明确表态:工具本身不是问题,问题在于实现方式。安全的用法:
- 用 AI 做研究、整理、内容大纲、融入第一方数据——提效但不替代人。
- 必须有经验丰富的 SEO 专家把关,避免“开了就不管”。
- 任何 AI 辅助内容仍要体现 E-E-A-T、提供信息增量,并按 Google 建议透明披露使用了 AI。
评估 AI 内容的灵魂 5 问:
- 这个页面真的因为有读者需要而存在,还是只为被搜索引擎/LLM 引用?
- 竞争对手用同样的 prompt 明天能产出几乎一样的页面吗?
- 如果 Google、记者、你的客户看到这个 AI 内容频道下所有 URL,你会心虚吗?
- 文章是否有偏见?有的话是否对用户透明?
- 页面是否提供了前 10 个结果里没有的第一方数据、专业知识或独到观点?
我的看法:结合之前的20 个全新域名,2000 篇纯 AI 文章和 Grokipedia 的 2 个案例,基本可以下结论:AI 批量内容可能短期有效,但大概 3~6 月开始下降,最后彻底跌回原形。
原文链接:It Works Until It Doesn't: AI Content Strategies That Backfire
【工具】结构化数据分析和建议工具
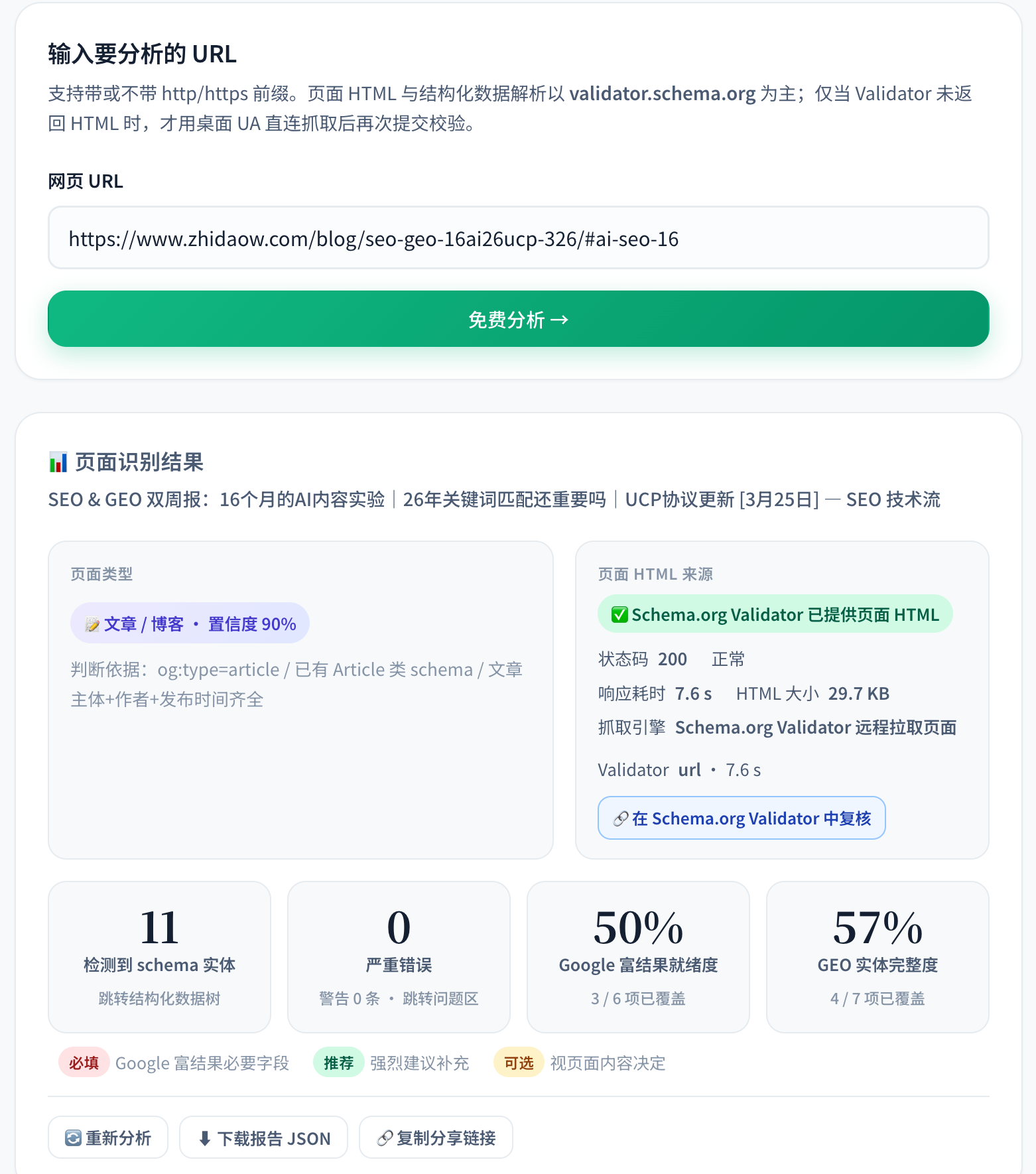
我新开发的免费工具,参考 schema.org 官方工具,可分析网页现有的结构化数据,结合网页类型并给出当前适合本页面的结构化数据建议。
工具地址:https://www.zhidaow.com/tools/structured-data-analysis/
欢迎试用,并给出使用建议。
评论
暂无评论,来写第一条吧 👇
写下你的评论