
[官方] Google 将"返回按钮劫持"列为新的处罚对象
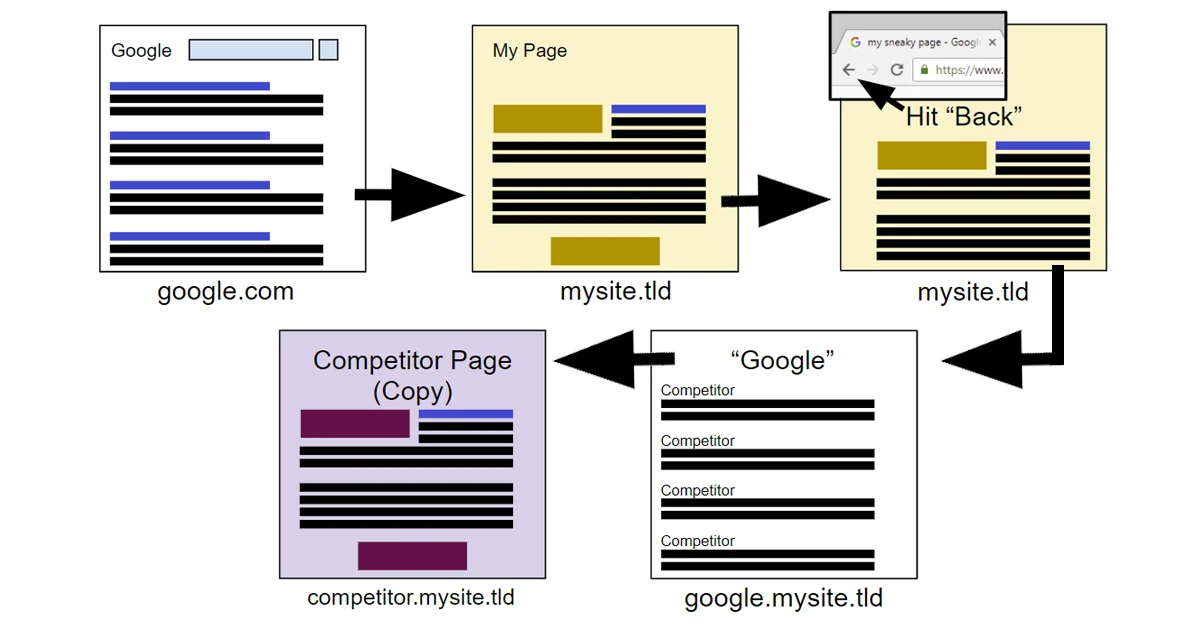
Google 近日宣布正式将"返回按钮劫持"(Back Button Hijacking)这一欺骗性行为列为"恶意行为"政策的明确违规项。违规网站将可能面临垃圾内容处罚,进而影响其在 Google 搜索中的排名表现。
新政策将于 2026 年 6 月 15 日正式生效,Google 提前两个月发布该政策,为站长预留调整时间。
1. 什么是"返回按钮劫持"?
当用户点击浏览器的"返回"按钮时,期望的是回到上一个访问过的页面。而"返回按钮劫持"行为正是打破了这一基本预期,具体表现包括:
- 干扰用户的浏览器导航功能
- 阻止用户通过返回按钮回到来源页面
- 将用户引导至从未访问过的页面
- 强制展示未经请求的推荐内容或广告
- 以其他方式妨碍用户的正常浏览行为
2. 为什么 Google 要采取行动?
Google 始终将用户体验放在首位。返回按钮劫持会造成以下负面影响:
- 干扰浏览器本身的功能
- 破坏用户预期的浏览流程
- 引发用户的挫败感与被操纵感
- 降低用户访问陌生网站的意愿
事实上,向用户浏览历史中插入欺骗性或操纵性页面的行为,一直都违反 Google Search Essentials。由于该类行为近期有所增加,Google 决定将其明确列为"恶意行为"政策的违规项。
Google 对"恶意行为"的定义是:
在用户预期与实际结果之间制造落差,导致负面且具有欺骗性的用户体验,或损害用户的安全与隐私。
存在返回按钮劫持行为的页面,可能会受到人工垃圾内容处罚或自动化降权的影响。
3. 网站所有者应如何应对?
Google 建议站长从以下几个方面进行自查与整改:
- 避免任何干扰浏览器历史记录的操作:确保网站不存在任何阻碍用户正常使用返回按钮的行为。
- 移除或禁用相关脚本:如果网站目前使用了在用户浏览历史中插入或替换欺骗性页面的脚本或技术,应立即停用。
- 排查第三方来源:返回按钮劫持的源头可能并非来自站点自身代码,而是来自引入的第三方库或广告平台。站长需要全面审查技术实现,包括代码、导入项和相关配置。
- 申请重新审核:若网站已受到人工处罚,且问题已修复完毕,可通过 Search Console 提交重新审核请求(Reconsideration Request)。
原文链接:https://developers.google.com/search/blog/2026/04/back-button-hijacking
[GEO]5 万次查询的调查:ChatGPT 会引用什么内容
1. 调查背景
AirOps 与 Growth Memo 合作,对 ChatGPT 的检索内容做了迄今最大规模的实证研究:
| 指标 | 数量 |
|---|---|
| 查询语句 | 16,851 条 |
| ChatGPT 响应次数(每条查询跑 3 次) | 50,553 次 |
| 抓取的页面 | 353,799 个 |
覆盖 10 个行业(出版、电商、旅游、健康、SaaS、房产、金融、法律、营销、商业服务)和 4 种查询类型(商业、信息、交易、本地)。
2. 四个核心发现
发现 1:检索排名(Retrieval Rank)是第一信号
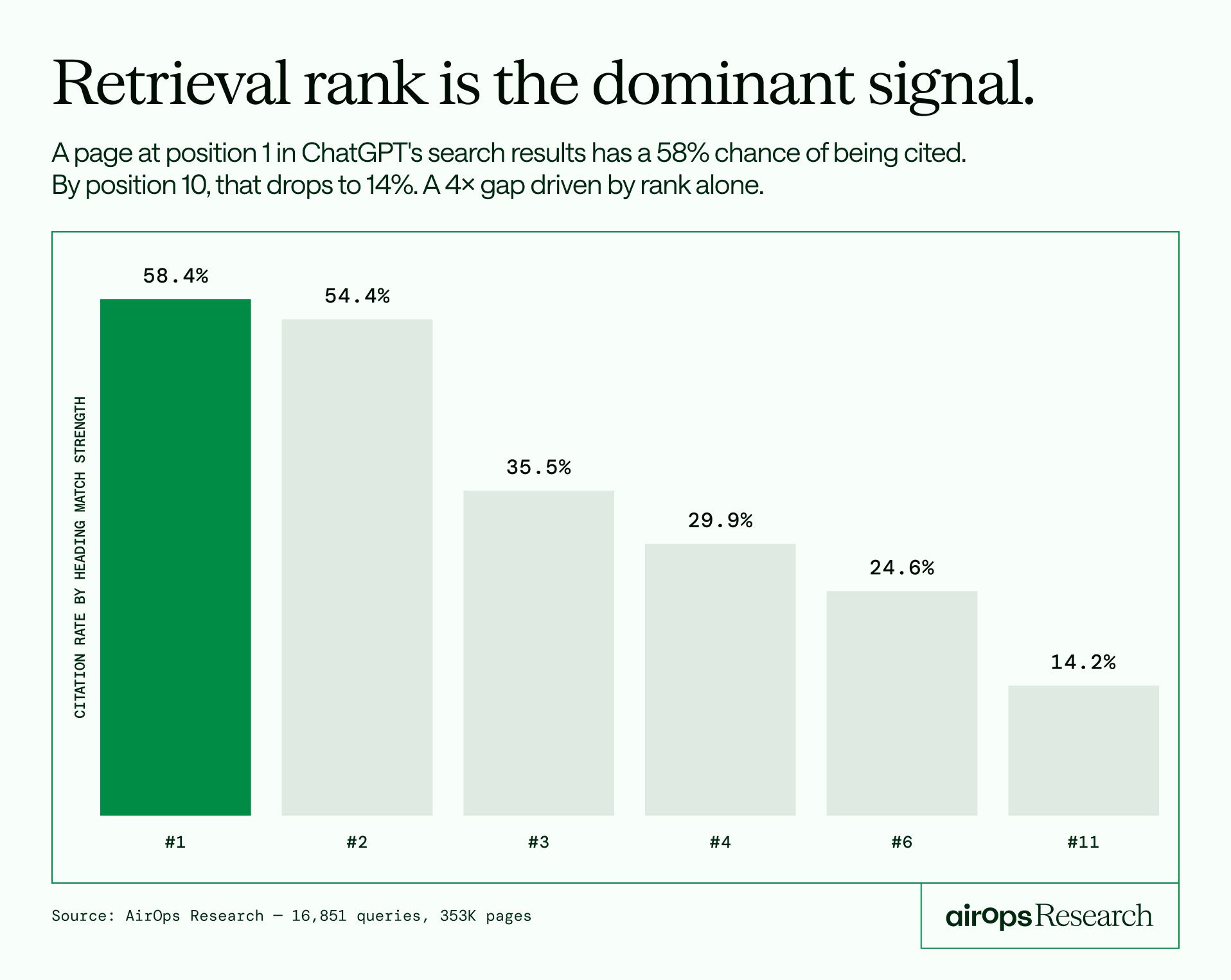
这里的检索排名,是指 ChatGPT 内部检索时从搜索引擎拿回的那一批候选 URL 的排名——类似于你在 Bing 或 Google 里搜索后得到的那个搜索结果页排序。
(每次用户提问时,ChatGPT 会从搜索引擎获取一些搜索结果,再结合训练过的内容,形成最终答案展示给用户。)
| 网络搜索排名 | 引用率 |
|---|---|
| 第 1 位 | 58.4% |
| 第 2 位 | 54.4% |
| 第 3 位 | 35.5% |
| 第 4 位 | 29.9% |
| 第 6 位 | 24.6% |
| 第 10 位 | 14.2% |
核心结论:排名第 1 位的引用率是排名第 10 位的 4 倍。
更直观的对比:一个内容平平但排第 1 的页面(55.9% 引用率),胜过一个内容极佳但排第 11 位之后的页面(21.5% 引用率)。
排名基本压倒了内容质量。
我的看法:在这里 SEO 排名对是否被 ChatGPT 引用的影响很大。
发现 2:标题匹配打败主题广度
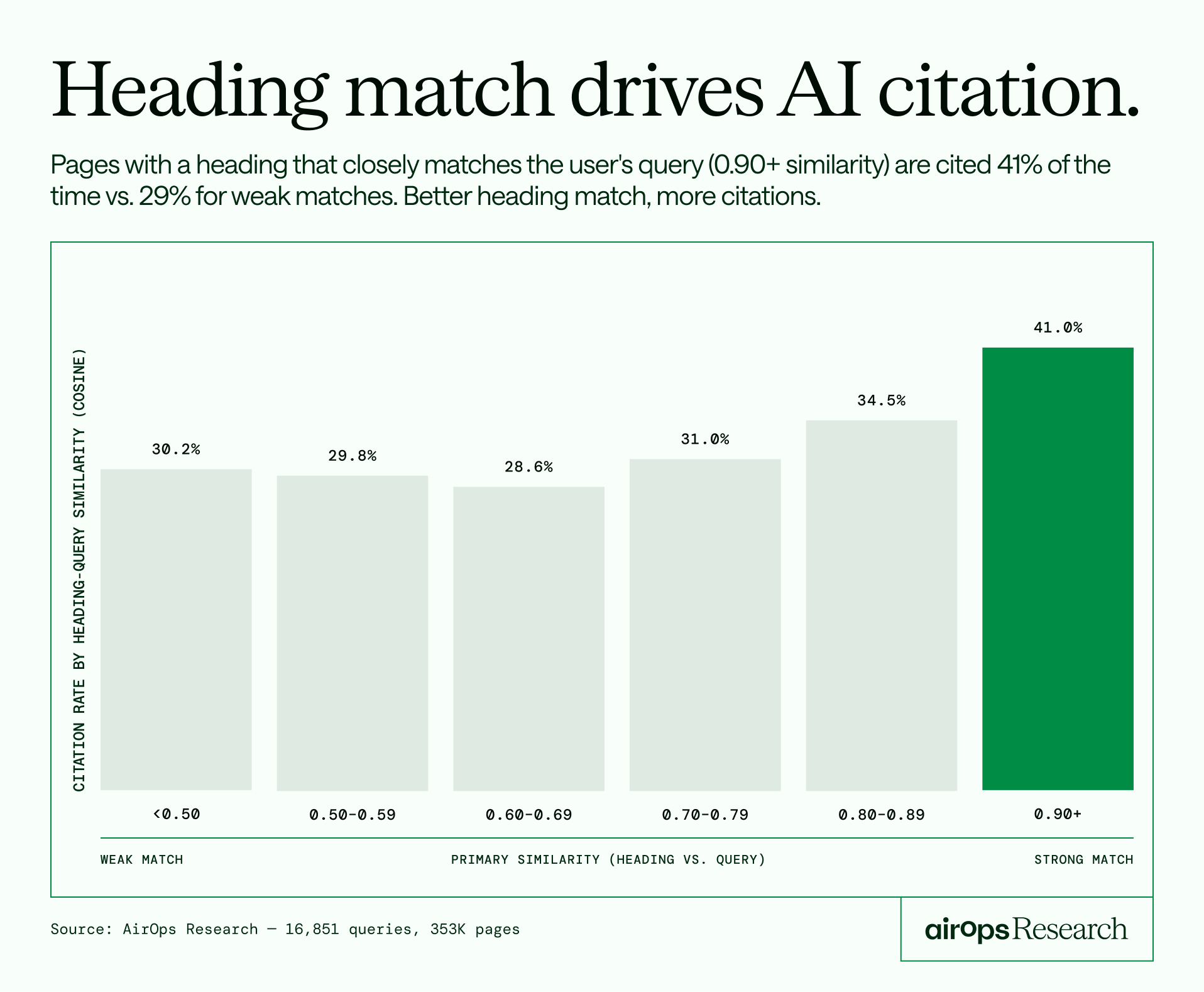
| 与查询的主要相似度 | 引用率 |
|---|---|
| < 0.50 | 30.2% |
| 0.70–0.79 | 31.0% |
| 0.80–0.89 | 34.5% |
| 0.90+ | 41.0% |
注:相似度在 0~1 之间,越接近 1 说明越相似。
一个反直觉的发现:当相似度都 ≥ 0.8 时,并不是覆盖度最高就更好。
| Fan-out 子话题覆盖率 | 引用率 |
|---|---|
| 0% | 35.5% |
| 26–50% | 38.2% ← 最优 |
| 100%("终极指南") | 34.0% ← 反而下降 |
结论:覆盖 26–50% 的子话题优于覆盖 100%。"Ultimate Guide"(终极指南)在 AI 时代反而是减分项。
我的看法:这里跟 SEO 就不同了,标题匹配的优先级很高,而且因为是段落索引,完整指南的效果下降了。
发现 3:域名权威(DA / Backlinks)不等于被 AI 引用
| 页面组 | 平均 DA | 平均反链 |
|---|---|---|
| 总是被引用 | 53.0 | 1.1M |
| 从不被引用 | 55.7 | 3.2M |
"总是被引用"的页面反而比"从不被引用"的反链少 3 倍、DA 更低。
同等高权威域名之间的巨大差异:
| 站点 | DA | 引用率 |
|---|---|---|
| YouTube | 100 | 2.4% |
| Wikipedia | 95 | 59.2% |
| Major News | 94 | 32.0% |
| 92 | 29.9% | |
| Health Publishers | 90 | 46.4% |
几乎相同的 DA,引用率却从 2.4% 到 59.2%——网站权重 DA 值并不等于 AI 引用。
我的看法:YouTube 和 Reddit 是特例,前者是无法被抓取,后者的用户内容虽然真实,但也主观,要谨慎使用。
发现 4:引用分布——要么赢、要么输
| 页面引用率 | 占比 |
|---|---|
| 0%(从不被引用) | 58.0% |
| 中间状态(1–99%) | 17% |
| 100%(总是被引用) | 24.7% |
总是被引用和从不被引用——几乎没有"中间地带"。而且"总是被引用"和"从不被引用"的页面内容画像几乎相同(字数、标题数、可读性、DA 都差不多),唯一的分水岭是检索排名。
3. 其他关键结论
Fan-out 查询数量
- 88.6% 的查询会触发正好 2 个子查询
- 8.8% 触发 0 个(简单实体/产品查询)
- 2.5% 触发 4 个及以上(复杂对比/评测查询)
- ChatGPT 每个回答平均引用 5–7 个来源
字数多少合适:500–2,000 词
| 字数 | 引用率 |
|---|---|
| < 500 | 30.5% |
| 500–999 | 34.3% ✅ 最优 |
| 1,500–1,999 | 33.5% |
| 5,000+ | 28.6% ← 反而低于 500 字以下 |
长内容在 AI 搜索中是减分项。
我的看法:因为 Token 限制,过长内容无法被抓取和识别了。
小标题几个合适:7–20 个 H2–H4
- 0 个 H2–H4:30.1%
- 1–3 个:28.0%(最差)
- 7–20 个:33.5–33.6%(最优)
- 21 个及以上:31.9%
例外:产品页面在 0 个副标题时引用率最高(43.2%)——因为产品页本身就聚焦一个主题。
结构化数据:效果明显
| JSON-LD 类型 | 引用率 |
|---|---|
| MedicalWebPage | 47.0% |
| BreadcrumbList | 46.2% |
| FAQPage | 45.6% |
| Organization | 44.3% |
| WebSite | 40.6% |
结构化数据 JSON-LD 的效果非常明显,带来独立的 +6.5% 增益,且不依赖其他信号。
可读性:大学级别最优
- 大学水平(16–17 岁):35.9%(最高)
- 儿童水平(< 8 岁):29.6%(最低)
ChatGPT 偏好专业级写作,而不是"小学生都看得懂"的语言。
内容时效性:30–89 天是黄金窗口
| 页面时效 | 引用率 |
|---|---|
| < 30 天 | 25.3%(新页尚未建立检索信号) |
| 30–89 天 | 32.8% ✅ |
| 90–179 天 | 32.4% |
| 2–5 年 | 27.5% |
| 5 年以上 | 27.6% |
行业差异:
- Finance(金融):新鲜度信号最强,差距 15%
- Travel(旅游):差距最大 19%
- E-commerce(电商):几乎不受新鲜度影响
- Health(健康):1–2 年老内容反而略胜新内容(医学权威感)
引用位置:41% 集中在回答前三分之一
- 前三分之一:40.7% 的引用
- 中间三分之一:34.8%
- 后三分之一:24.5%
每个被引用的页面每次回答只被引用 1 次——密度不会带来多次引用。
我的看法
这篇文章的研究结论和之前的一些结论是有差异的。就比如网站权重这部分,我记得之前有文章说网站权重是影响引用的重要因素。
我认为这些差异,排除掉研究方法之外,主要是因为 AI 也在不断变化,不同 AI 的引用因素也不一样。因此更严谨的方法是,将这些因素视为特定平台的、且是当前阶段的有效策略。
如果要追求长期策略的话,肯定还是取决于:
- 内容的质量:EEAT
- 品牌的建立和传播
- 营销层面的广度、深度和可信度等
原文链接:https://www.airops.com/report/the-fan-out-effect-what-happens-between-a-query-and-a-citation
[调研]消费者如何在 AI Mode 中进行高风险决策购物
1. 核心结论
AI Mode 正在压缩消费者"对比、排除、发现品牌"的购物阶段。
三大核心发现:
- 74% 的 AI Mode 最终候选名单直接来自 AI 输出——没有外部核验、没有交叉对比、没有第二意见
- 88% 的用户完全接受 AI 的候选名单——而在传统搜索中,56% 的用户自己从多个来源构建候选名单
- 用户不觉得被限制——AI Mode 中"选项过窄"的不满率 15%,传统搜索 11%,统计上无显著差异。用户没有感到被"困住",他们是满意地接受
2. 研究方法
- 48 名美国参与者
- 185 个高风险购物任务
- 4 个品类:电视、笔记本、洗衣机烘干机套装、汽车保险
- A/B 测试:每人同时使用 AI Mode 和传统搜索
- 149 个 AI Mode 任务 + 36 个经典搜索任务
- 屏幕录制 + 音频 + 训练过的分析师人工标注
3. 六大关键发现
发现 1:88% 用户完全接受 AI 的推荐名单
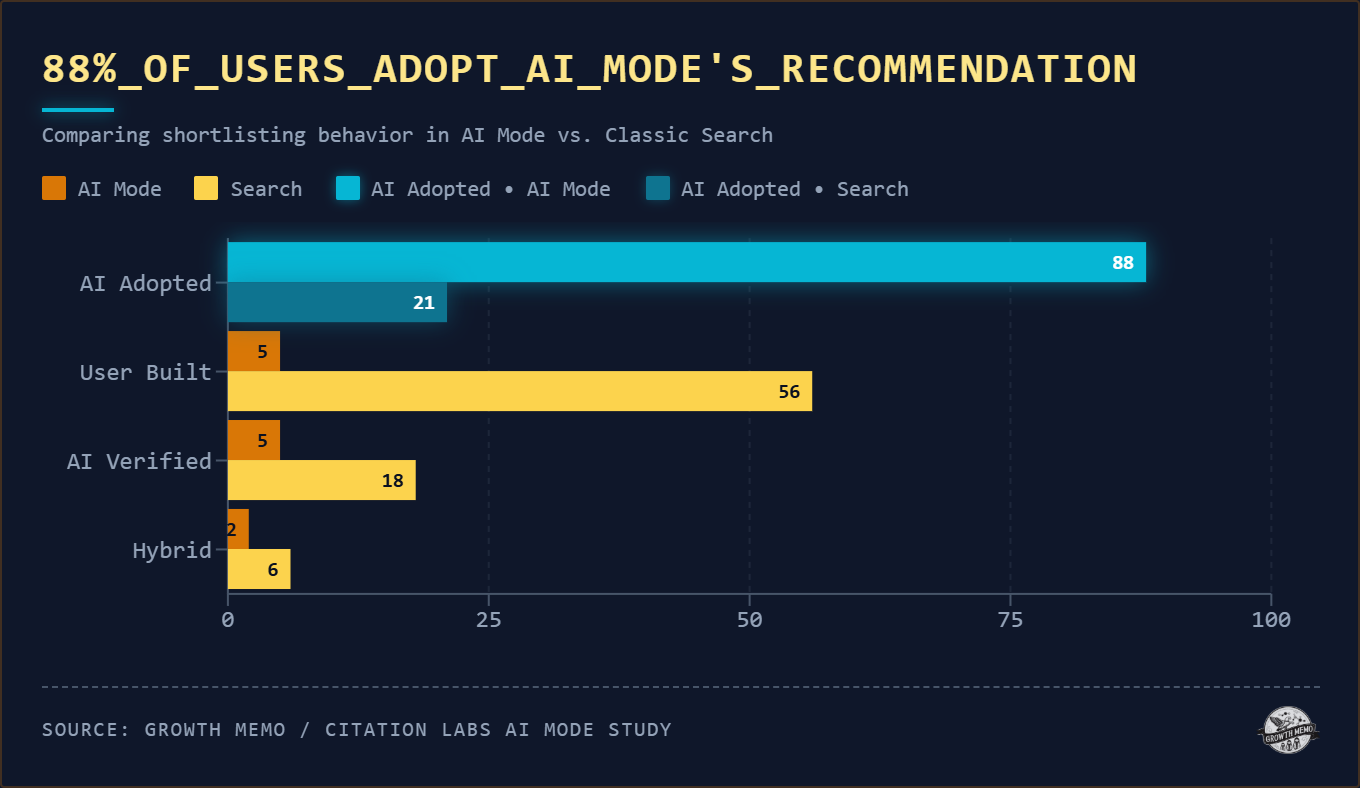
| 行为 | AI Mode | 传统搜索 |
|---|---|---|
| 用户自建决策名单 | 5.4% | 56% |
| 直接采纳 AI 短名单 | 88% | 不适用 |
| 整个任务中零点击 | 64% | — |
| 任务中点击过内容 | 36% | 89% |
启发:
- AI Mode 不只是"搜索工具",还是"推荐工具"
- 自建决策名单的用户平均多花 89 秒、消耗 2 倍以上的来源——用户为了省这 89 秒,主动放弃了自主对比
- 对品牌而言:进不了 AI 的候选名单 = 在 64% 的零点击用户面前不存在
发现 2:74% 的用户选择了 AI 排第一的品牌
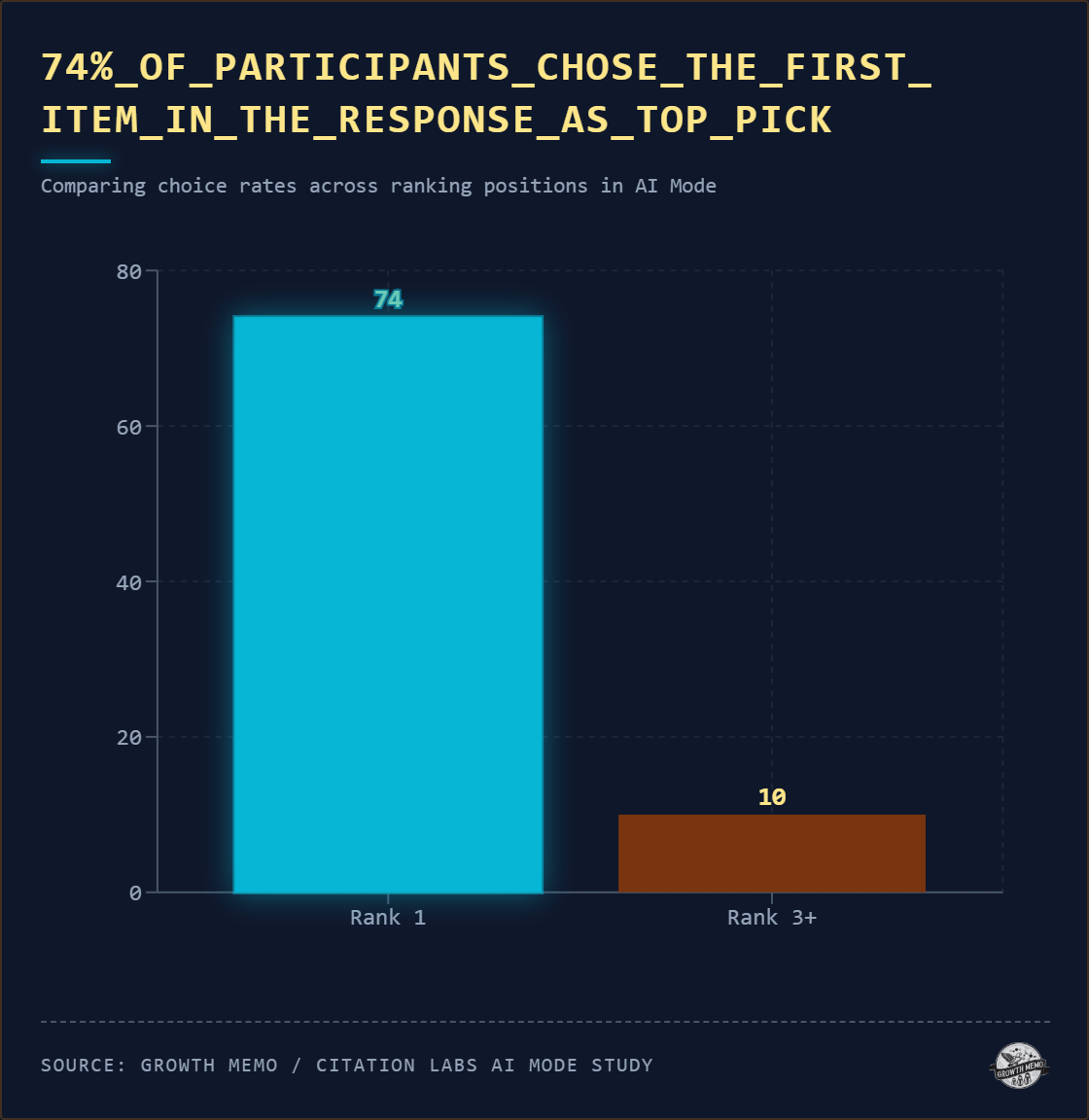
- 用户最终选择的平均排名:1.35
- 只有 10% 选择排名第三或更低的品牌
- AI 的"排名第一"优势被放大了,因为它已经做过过滤,呈现的推荐名单通常只有 2–5 项
启发:
- 在 AI Mode 中,位置即目标——把"在关键 prompt 中挤进 Top 1"作为核心 KPI
- 26% 的品牌认知"逃逸率"说明:预搜索的品牌建设依然重要——在用户到达 AI 之前就已经在他们脑子里占一席之地(所谓品牌认知逃逸,是指用户在列表靠后位置发现熟悉品牌时,无论 AI 把它放在哪儿都会优先选择它)
发现 3:AI 的表述变成了信任信号
| 信任驱动因素 | AI Mode | 传统搜索 |
|---|---|---|
| AI 表述 | 37% | 几乎不存在 |
| 品牌认知 | 34% | — |
| 多方比对 | 5% | 主导机制 |
分类差异:
- 电视、笔记本(用户有先验偏好):品牌认知主导
- 保险、洗烘(用户无先验偏好):AI framing 主导
最具代表性的用户原话:
"[保险品牌 A] 和 [保险品牌 B] 告诉我具体是多少钱,[保险品牌 C] 和 [保险品牌 D] 只给百分比。知道确切数字让我一下子就想选 [保险品牌 A] 或 [保险品牌 B]。"
启发:当用户没有先验观点时,AI 的表述就是信任信号本身。
发现 4:不在 AI 列表里 = 不存在
核心结论:AI Mode 的品牌结果高度集中,没进入列表就没有任何机会。
另外:
- AI Mode 中出现了不熟悉的品牌时,多名参与者仅凭没听说过就直接排除
- 也有参与者因为 AI Mode 中某品牌没有超链接,就淘汰掉了
- 关键反直觉发现:尽管候选变窄了,用户并没有觉得被限制(关于受限感,AI Mode 中 15%,传统搜索 11%,差别不大)
发现 5:用户离开 AI Mode 是为了买,不是为了研究
核心结论:AI Mode 用户离开的动机是确认交易,而不是探索候选。
| 跳出行为 | AI Mode | 传统搜索 |
|---|---|---|
| 访问外部网站 | 23% | 67% |
| Reddit 访问 | 1.3% | 19% |
意图差异才是关键:
- AI Mode 用户离开时:去零售商/厂商页,为已选候选核验价格或规格
- 传统搜索用户离开时:去 Reddit 看用户评论、去评测站看专家观点、去对比工具做对比——为发现候选
发现 6:三大杠杆——可见性、表述、定价数据
- 模型层可见性:AI Mode 不显示品牌,这个品牌就不存在。
- AI 的表述方式:AI 怎么描述你,和"是否提到你"同样重要。带具体属性(型号、价格、命名用例)的品牌位置更强。
- 结构化价格数据:实体商品走 Merchant Center feeds + 结构化数据 schema;服务走"编辑式"——在落地页/FAQ 把定价表述为条件式("你的费率取决于 X、Y、Z")。
原文链接:https://www.growth-memo.com/p/how-consumers-navigate-high-stakes
我的看法
我在使用 AI 时也会提问一些产品相关问题,确实非常容易受到 AI 的影响,尤其是当面对一个我没有认知品牌的品类时。
我默认会认为 AI 给出的答案是经过大数据整理、筛选和过滤的,推荐的产品可以视作一种“精选”,即使我自己去调查,可能也会得到类似的结果,所以我的决策很容易受到 AI 答案的影响。
不过,对于我已有认知的品牌,我还是会更相信自己的判断。比如选购跑鞋时,我就倾向于从自己熟悉的品牌中去挑选。
[工具] AI 提示词模拟工具
我新做的 AI 提示词模拟工具,只需要输入一个关键词,就可以模拟真实用户在 AI Chat(ChatGPT、Claude、Perplexity、DeepSeek、通义千问等)中围绕它的提问语句,按用户旅程分组呈现。
如果你想让品牌出现在用户提问中,你必须先了解目标客户在 AI 中怎么提问?这个工具就是围绕关键词(如产品、服务、概念、工具名等),模拟用户的提问,可免费使用。
以下是效果截图:
备注
- 头图来自 INS 的 _yes_but。
评论
暂无评论,来写第一条吧 👇
写下你的评论